
Machines Moving Molecules: My Software Internship at Octant
Machines Moving Molecules: My Software Internship at Octant
This summer I had the opportunity to try out my first ever biotech internship at Octant, which was truly awesome! Going into the internship, I was filled with nervous excitement and a ton of questions-- will I know enough science to understand how things work? How different will the culture be compared to a traditional tech company? What the heck does Octant actually do? Now that I’m at the end of my internship, I can definitely say that it’s been an amazing experience; I’ve learned so much while contributing to Octant’s goals and building relationships.
On the first day of my internship I was informed that Octant was going on an off-site retreat and I was invited! Though I was a bit apprehensive of diving straight into meeting the entire company without any sort of onboarding, everyone was so welcoming! At the off-site in Monterey we had a fun series of Beach Olympics games, biked along the shoreline and ate tons of delicious food! The best part was getting to know each Octonaut-- we even went out to karaoke at a local bar! With this introduction to Octant, I immediately knew that its culture was special. It seemed like a fun, young startup where everyone loved to work hard but also play hard!

Upon returning from the offsite, I got to work on a few onboarding tickets in the Django monorepo (described here) to get familiar with the codebase. I was also introduced to my primary project for the summer - rebuilding ChemHub, a tool used by our HT (high-throughput) Chemistry team for building chemical libraries. The HT Chemistry team builds these libraries by reacting a “core” (putative target binder custom synthesized to include a reactive handle) with our fragment collection. This yields ~10k unique products, which are then screened for activity against clinically relevant targets on our multiplexed assay platform. We hope that someday one of these compounds will become a bona fide drug!

The above diagram shows the first few steps of this process at a smaller scale. At Octant’s scale, though, we’re dealing with tens of thousands of products. As you can imagine, it would be extremely difficult for a scientist to manually synthesize a full chemical library of this scale. We use lab automation to help with this issue. For example, we use the Echo Liquid Handler which can transfer liquids at nanoliter scale using sound waves!

The Echo “knows” what to do by reading a CSV containing information about the desired transfers, like where to move the liquid to/from and in what amount. Back when we were synthesizing much smaller libraries, the HT Chem team would create these CSV tables manually. That process is painful and prone to human error, though, and it doesn’t scale well, so our Compute team built some tools to help automate this process.
Originally ChemHub, an R Shiny App that ran on our onsite servers, was built to solve this problem. However, over time, we’ve built up our Compute platform’s capabilities on Argo, Octant’s Django/React-based web portal for experimental design. For more info check out former intern Justin Wise’s blogpost! This web application interacts with our custom database, which contains information on chemical/biological inventory, screening data for discovery programs, and more. By migrating ChemHub to Argo we could avoid having to maintain bespoke tools with different tech stacks, and also leverage our database to design more sophisticated experiments, such as building libraries based on previous screening results.
Over the course of the internship, I got to learn a ton about synthetic chemistry, best practices for API design, working with Pandas to manipulate data frames, and harnessing React on the frontend side. The result became a new application within Argo, which we fondly named Chiron, after the wise centaur from Greek mythology that taught many of the Argonauts subjects like chemistry (our compute team has been naming things after adventure stories in Greek mythology).
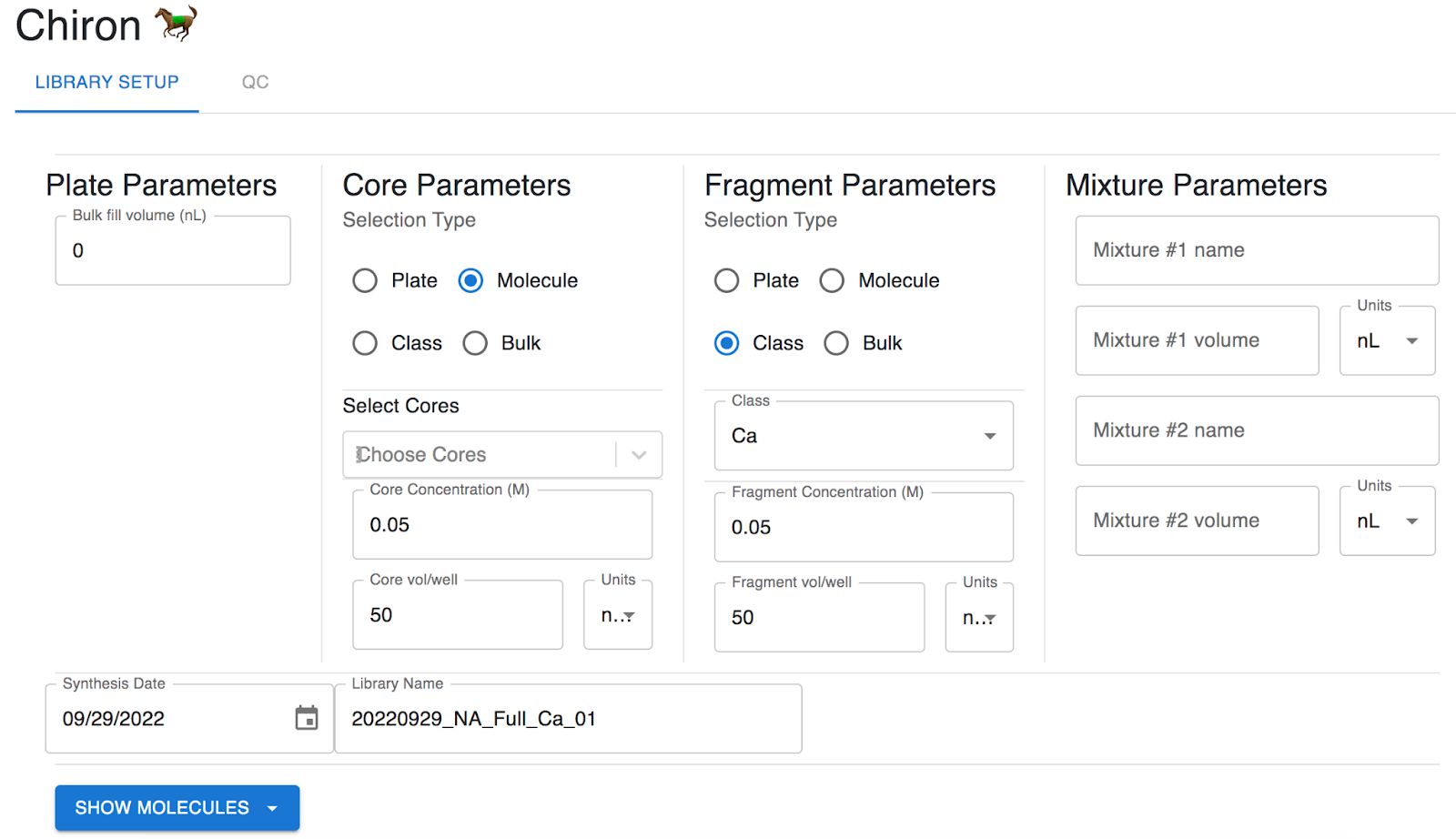
The interface shown above allows scientists to easily create the desired CSVs for machines around the lab such as the Echo or the LC-MS (liquid chromatography–mass spectrometry). This speeds up our drug discovery process at both the library synthesis and library QC steps. The scientists seemed really excited to work with Chiron after I gave a demo at a company-wide meeting! In addition to the cutting edge science and technology, Octant has tons of cool people and fun events! I thoroughly enjoyed all of the Octonaut-hosted activities from themed Happy Hours to flag football and run club!
Over the summer I was able to level up my software skills and learn more about the chemistry/biology side of the company, which was super interesting! I appreciated the chance to work closely with scientists at Octant, since that was something I had never done before. I’d like to thank the Compute team, the HT Chemistry team and the entirety of Octant for an epic summer; I had a blast! If you’re considering entering the biotech field and want to try it out at a company where software is making a serious impact-- I can’t recommend Octant highly enough!
Citations
1. Ramström, O., & Lehn, J.-M. (2002). Drug discovery by dynamic combinatorial libraries. Nature Reviews Drug Discovery, 1(1), 26–36. doi:10.1038/nrd704
